为构建者提供 AI 编码工具的接入、额度与使用支持,适配命令行、插件、桌面端和多 Agent 工作流。
你只管想好做什么,Agent 负责把它做出来。
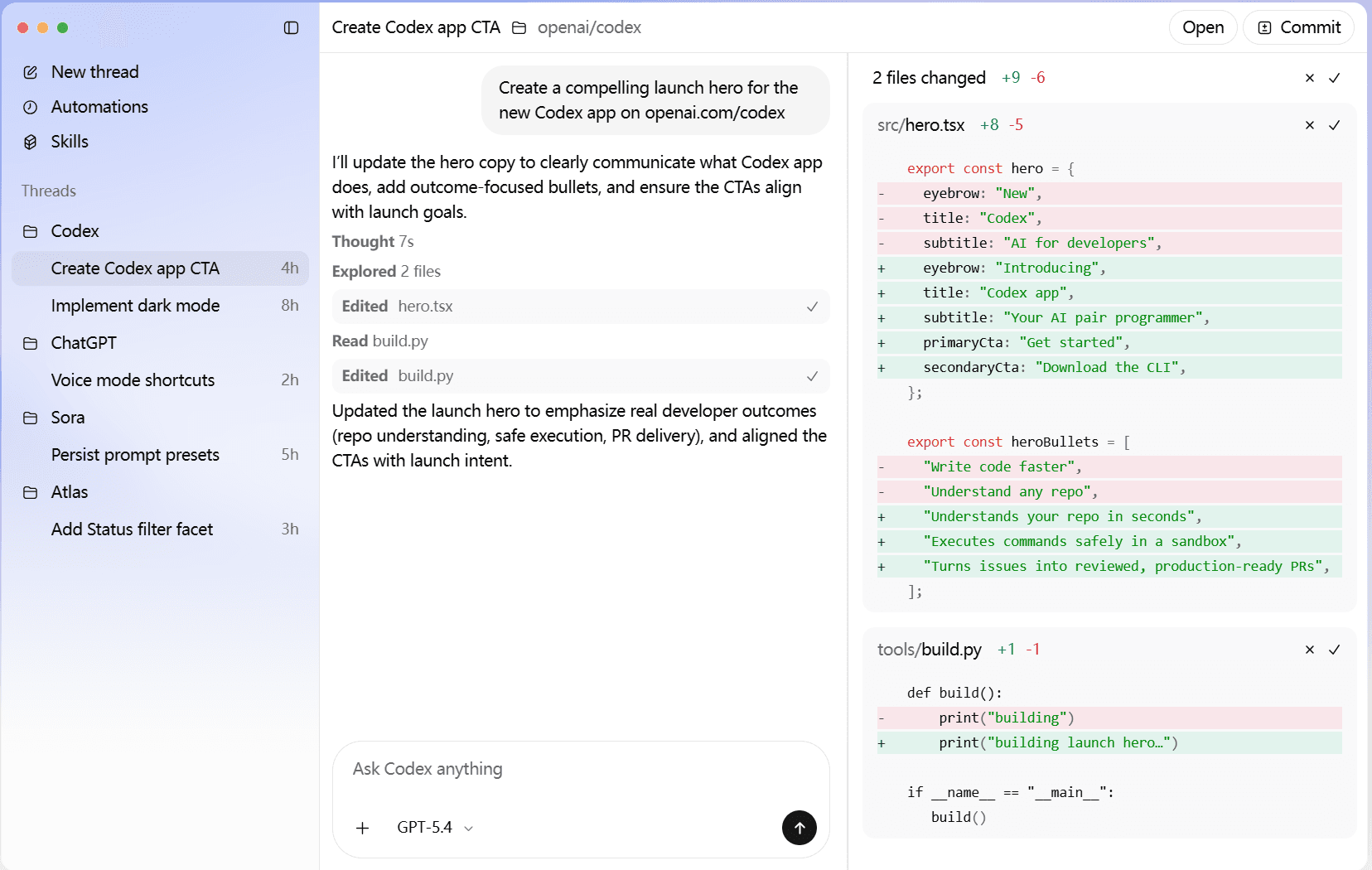
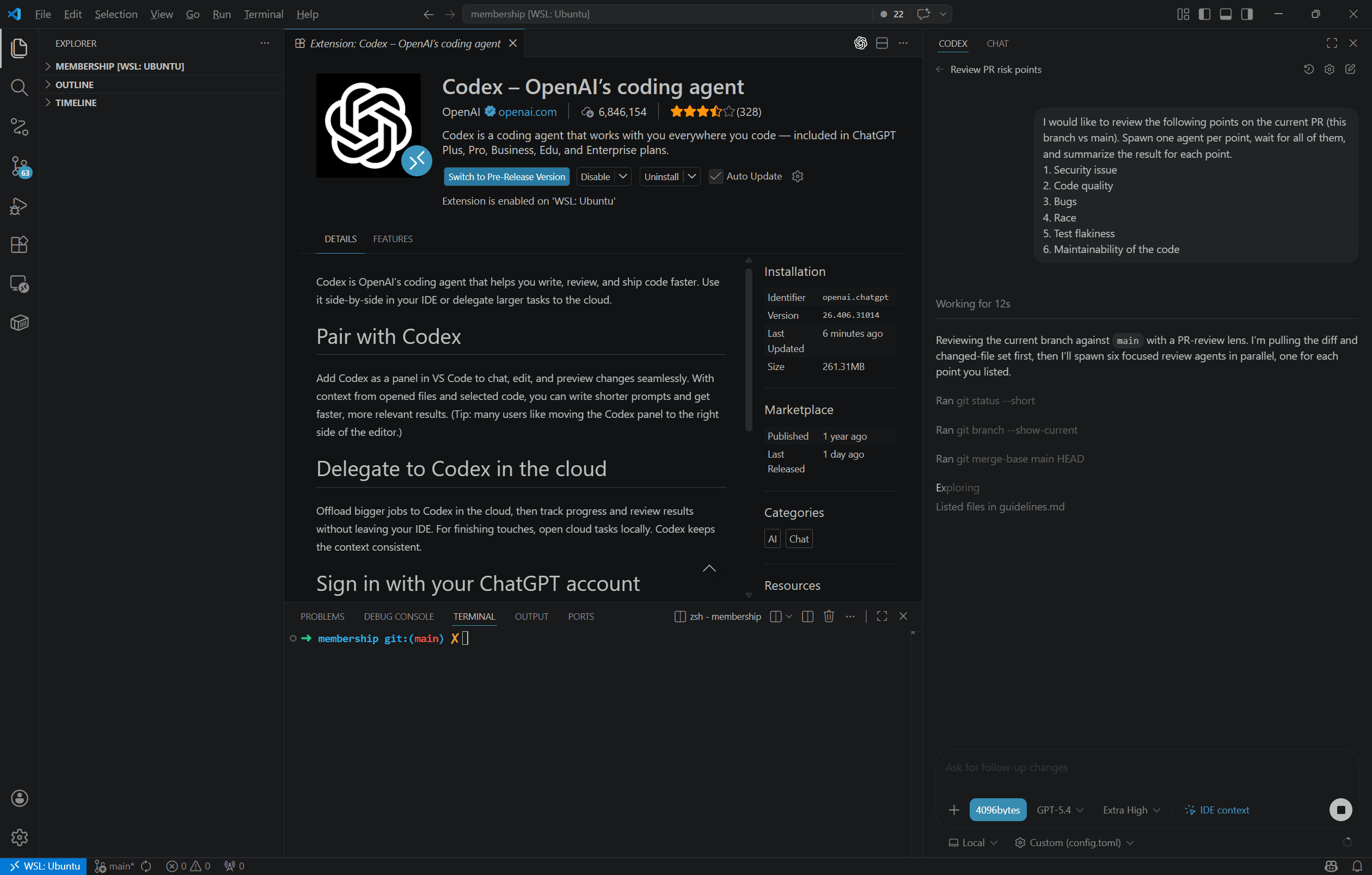
UI 演示仅用于说明 Codex CLI 的核心工作流程,完整功能请以官方发布的 Codex CLI 原版为准。4096Bytes 仅提供生产级接入方案,旨在适配原生 CLI 及多端开发环境。
打破工具边界。用一个 API Key,构建你自己的 AI 协作空间。
延续 CLI 的硬核基因,通过 Harness 架构驾驭 AI 潜能,适配多端协作场景。从终端到桌面,始终与您的代码同行。
为什么选择 4096Bytes
面向高频 AI 编码工作流的吞吐、缓存、路由与计费可视化能力。
吞吐能力
500k+
每分钟 Tokens
高峰请求就绪
上下文缓存
最高降低 90%
自动上下文持久化
热缓存复用
智能路由
99.9%
可用性 SLA
故障切换在线
透明计费
实时
USD 账单/指标
实时花费计量
按使用阶段选择你的接入方案
先低门槛试,再稳定开发,最后按部署规模走向独享集群。三档方案覆盖个人到企业的不同工作强度。
尝鲜日卡
¥19.90 / 单日
核心额度 · $100 USD 每日额度
- 适用场景 临时救急 / 效果评测
- 极高响应优先权
- 国内直连免魔法
专业月卡
¥368 / 每月
核心额度 · $200 USD 每日额度
- 适用场景 深度开发 / 长期项目
- 包含尝鲜日卡的所有权益
- 高并发 (Agent 舰队支持)
- 比按天购买更划算
- 能扛住全天高强度开发
企业定制
联系客服
核心额度 · 独享高额配额
- 适用场景 大规模部署 / 专属集群
- 独立计算集群部署
- 专属 SLA 与白手套服务
模型调用成本换算
下面按 1M tokens 展示输入、输出与缓存命中的美元成本,方便你把 Codex / GPT 的调用量直接换算成钱。
所有价格均按每 100 万 tokens 计费。
模型名称
输入 (1M)
输出 (1M)
缓存折扣
GPT-5.4最新
输入 (1M)$2.50
输出 (1M)$15.00
缓存折扣-90%
GPT-5.3-Codex
输入 (1M)$1.75
输出 (1M)$14.00
缓存折扣-90%
GPT-5.2-Codex
输入 (1M)$1.75
输出 (1M)$14.00
缓存折扣-90%
GPT-5.1-Codex-Max
输入 (1M)$1.25
输出 (1M)$10.00
缓存折扣-90%
GPT-5.2
输入 (1M)$1.75
输出 (1M)$14.00
缓存折扣-90%
GPT-5.1-Codex-mini
输入 (1M)$0.25
输出 (1M)$2.00
缓存折扣-90%
GPT-5.3-Codex-Spark预览
输入 (1M)待定
输出 (1M)待定
缓存折扣待定
* GPT-5.3-Codex-Spark 目前仍是 Codex 研究预览版,OpenAI 还没有公布最终的 token 价格。
常见问题
把访问、额度、安全和订阅这几件最常被问到的问题一次讲清楚,方便您在接入前快速判断。
FAQ Topic
网络与访问
不需要。我们专门优化了中转线路,支持国内直连,确保你在 VS Code 或 IDE 中感知不到延迟。